FairSHAP: Preprocessing for Fairness Through Attribution-Based Data Augmentation
{kind=link}
Abstract
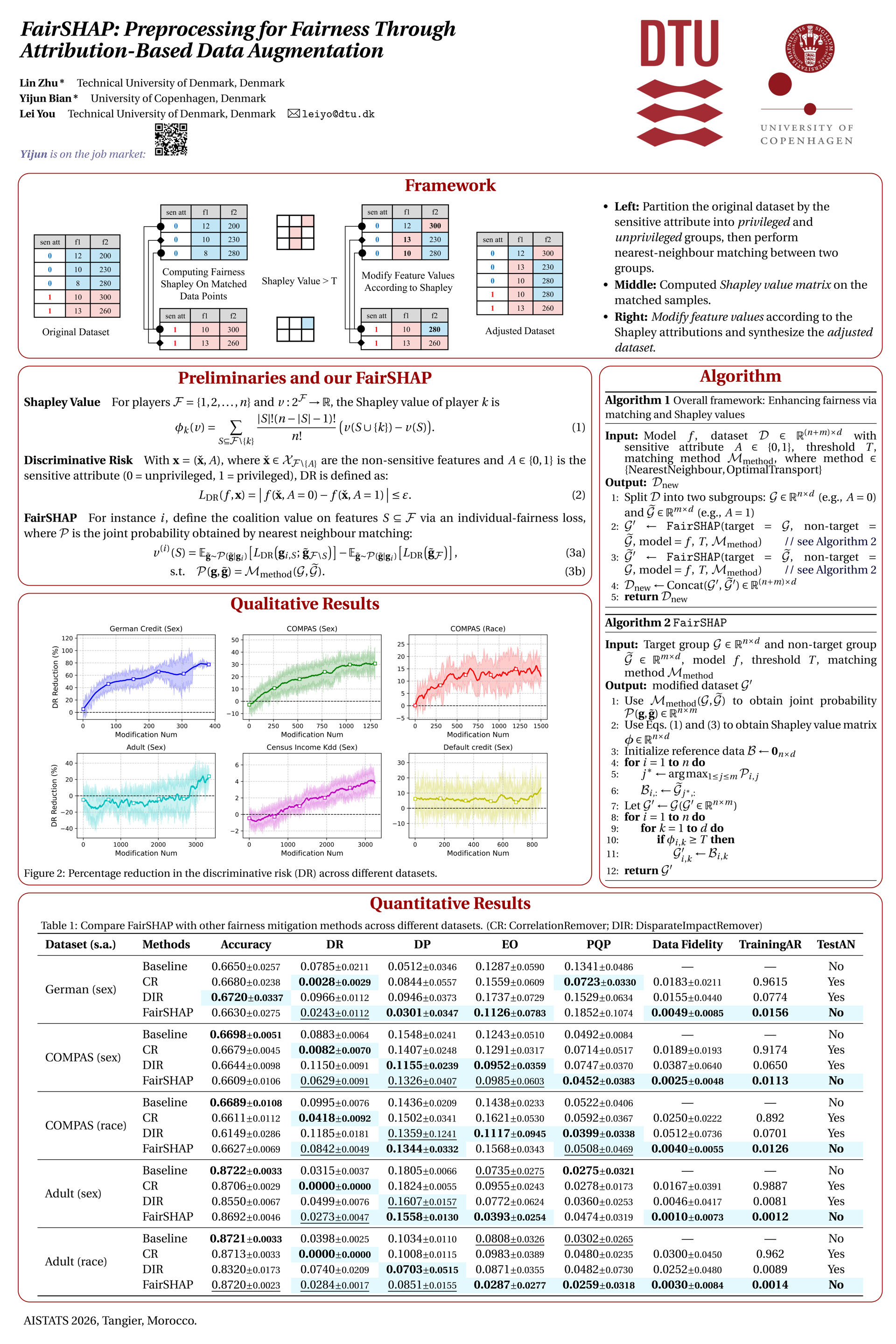
Ensuring fairness in machine learning models is critical, particularly in high-stakes domains where biased decisions can lead to serious societal consequences. However, existing preprocessing approaches generally lack transparent mechanisms for identifying which features are responsible for unfairness. This obscures the rationale behind data modifications. We introduce FairSHAP, a novel preprocessing framework that leverages Shapley value attribution to improve both individual and group fairness. FairSHAP identifies fairness-critical features in the training data using an interpretable measure of feature importance, and systematically modifies them through instance-level matching across sensitive groups. Our method effectively reduces discriminative risk (DR) with an instance-wise guarantee up to an interaction residual term, which is bounded under local matching, while simultaneously bounding the upper limit of demographic parity (DP), which in practice leads to its reduction. Experiments on multiple tabular datasets show that we achieve state-of-the-art or comparable performance across DR, DP, and equality of opportunity (EO) with minimal modifications, thereby preserving data fidelity. As a model-agnostic and transparent method, FairSHAP integrates seamlessly into existing machine learning pipelines and provides actionable insights into the sources of bias. Our code is available on https://github.com/ZhuMuMu0216/FairSHAP.