Meta Learning in Bandits within shared affine Subspaces
Steven Bilaj ⋅ Sofien Dhouib ⋅ Setareh Maghsudi
2024 Poster
{kind=link}
Abstract
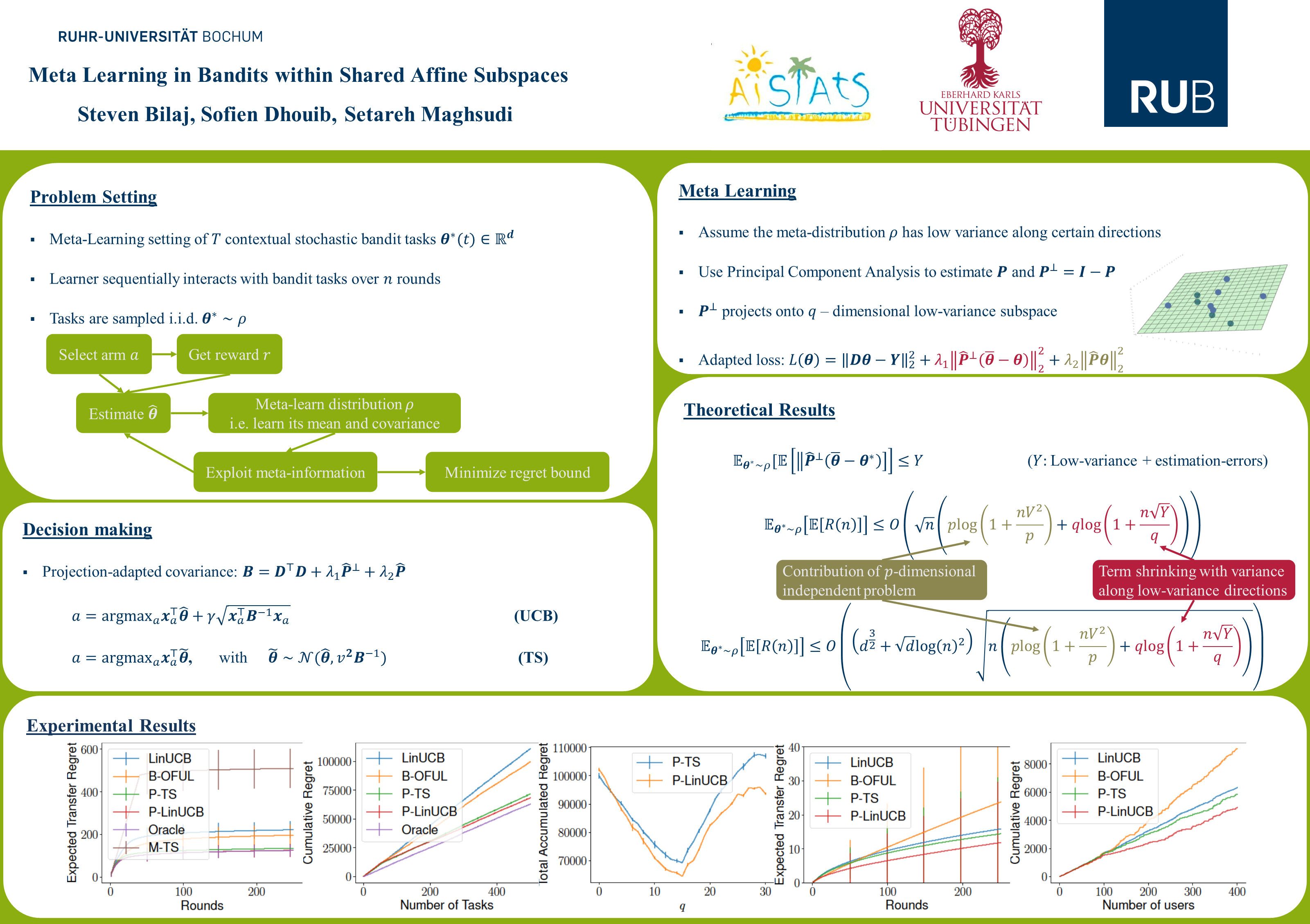
We study the problem of meta-learning several contextual stochastic bandits tasks by leveraging their concentration around a low dimensional affine subspace, which we learn via online principal component analysis to reduce the expected regret over the encountered bandits. We propose and theoretically analyze two strategies that solve the problem: One based on the principle of optimism in the face of uncertainty and the other via Thompson sampling. Our framework is generic and includes previously proposed approaches as special cases. Besides, the empirical results show that our methods significantly reduce the regret on several bandit tasks.
Chat is not available.
Successful Page Load