A Cubic-regularized Policy Newton Algorithm for Reinforcement Learning
Mizhaan Maniyar ⋅ Prashanth L.A. ⋅ Akash Mondal ⋅ Shalabh Bhatnagar
2024 Poster
{kind=link}
Abstract
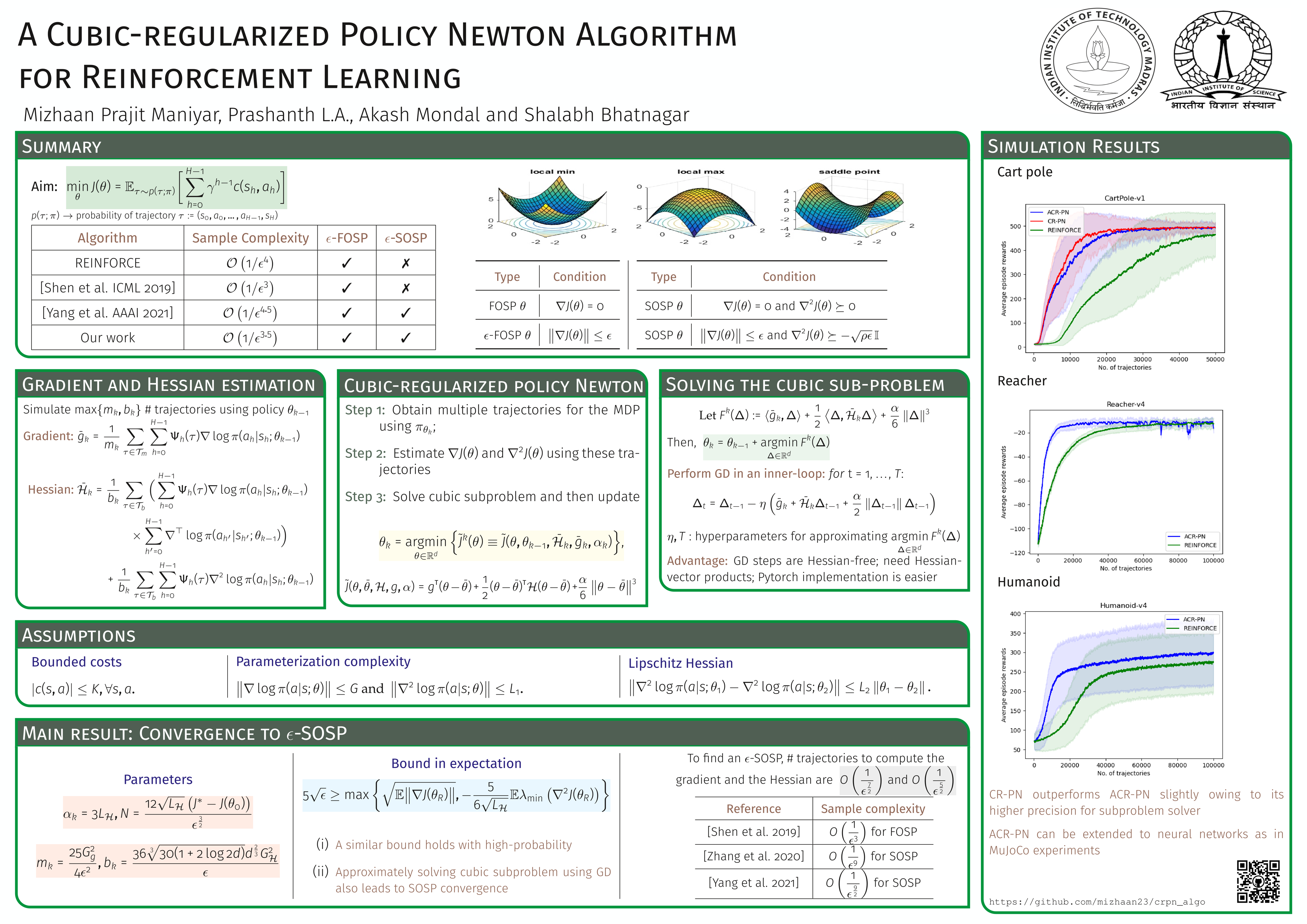
We consider the problem of control in the setting of reinforcement learning (RL), where model information is not available. Policy gradient algorithms are a popular solution approach for this problem and are usually shown to converge to a stationary point of the value function. In this paper, we propose two policy Newton algorithms that incorporate cubic regularization. Both algorithms employ the likelihood ratio method to form estimates of the gradient and Hessian of the value function using sample trajectories. The first algorithm requires an exact solution of the cubic regularized problem in each iteration, while the second algorithm employs an efficient gradient descent-based approximation to the cubic regularized problem. We establish convergence of our proposed algorithms to a second-order stationary point (SOSP) of the value function, which results in the avoidance of traps in the form of saddle points. In particular, the sample complexity of our algorithms to find an $\epsilon$-SOSP is $O(\epsilon^{-3.5})$, which is an improvement over the state-of-the-art sample complexity of $O(\epsilon^{-4.5})$.
Chat is not available.
Successful Page Load