A Greedy Approximation for k-Determinantal Point Processes
Julia Grosse ⋅ Rahel Fischer ⋅ Roman Garnett ⋅ Philipp Hennig
2024 Poster
{kind=link}
Abstract
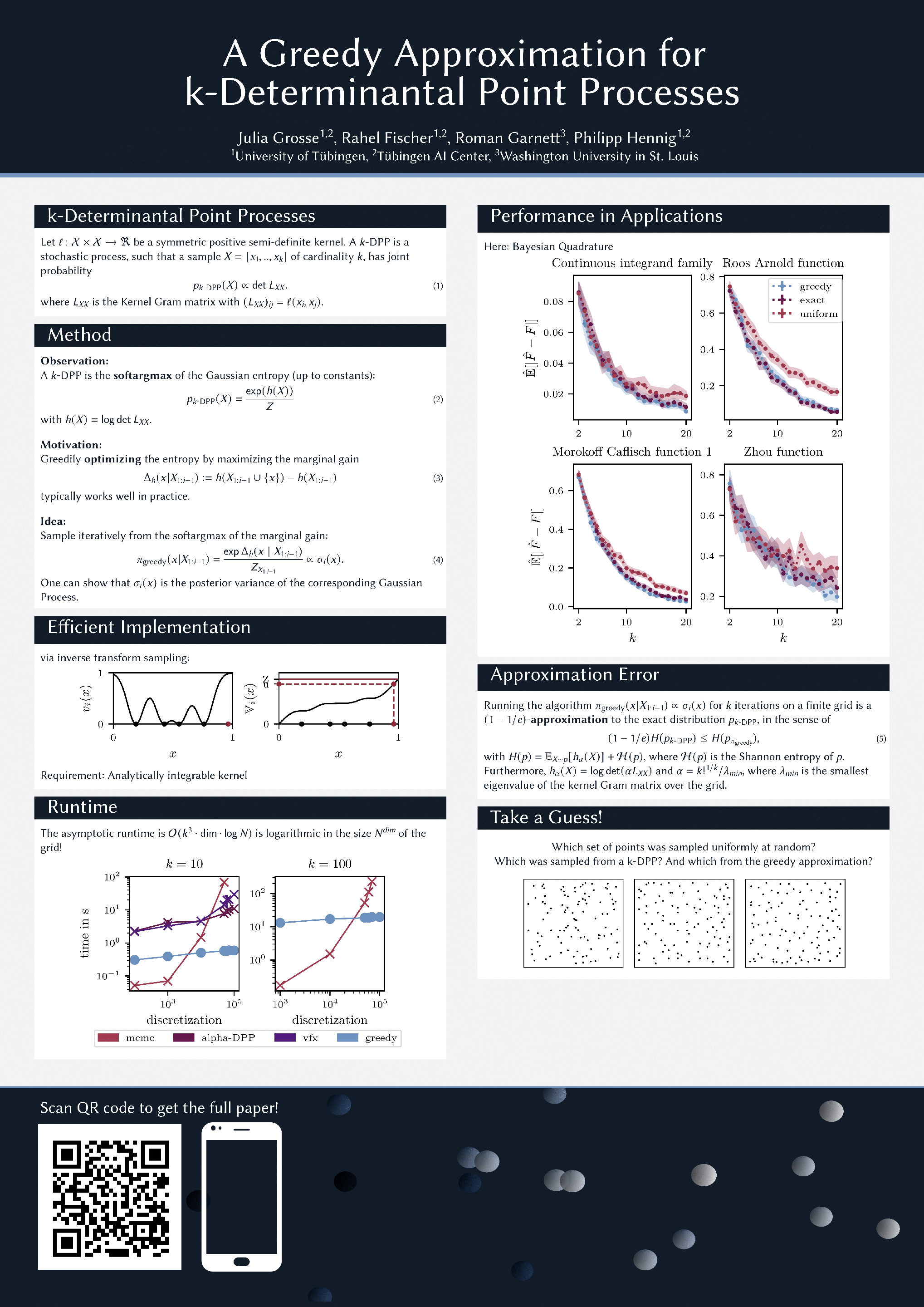
Determinantal point processes (DPPs) are an important concept in random matrix theory and combinatorics, and increasingly in machine learning. Samples from these processes exhibit a form of self-avoidance, so they are also helpful in guiding algorithms that explore to reduce uncertainty, such as in active learning, Bayesian optimization, reinforcement learning, and marginalization in graphical models. The best-known algorithms for sampling from DPPs exactly require significant computational expense, which can be unwelcome in machine learning applicationswhen the cost of sampling is relatively low and capturing the precise repulsive nature of the DPP may not be critical. We suggest an inexpensive approximate strategy for sampling a fixed number of points (as would typically be desired in a machine learning setting) from a so-called $k$-DPP based on iterative inverse transform sampling. We prove that our algorithm satisfies a $(1 - 1/\epsilon)$ approximationguarantee relative to exact sampling from the $k$-DPP, and provide an efficient implementation for many common kernels used in machine learning, including the Gaussian and Mat\'ern class. Finally, we compare the empirical runtime of our method to exact and Markov-Chain-Monte-Carlo (MCMC) samplers and investigate the approximation quality in a Bayesian Quadrature (BQ) setting.
Chat is not available.
Successful Page Load