Imposing Fairness Constraints in Synthetic Data Generation
{kind=link}
Abstract
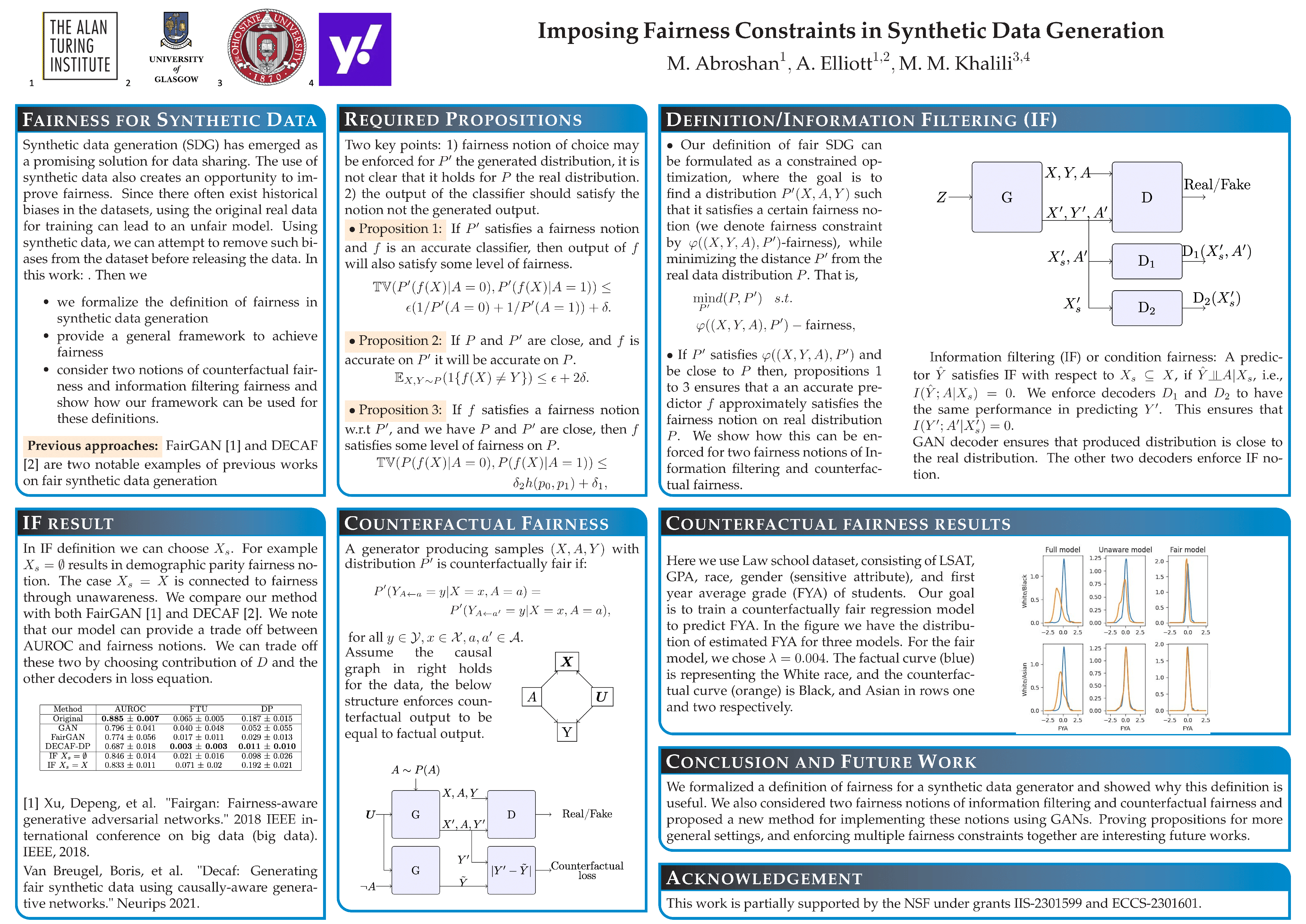
In several real-world applications (e.g., online advertising, item recommendations, etc.) it may not be possible to release and share the real dataset due to privacy concerns. As a result, synthetic data generation (SDG) has emerged as a promising solution for data sharing. While the main goal of private SDG is to create a dataset that preserves the privacy of individuals contributing to the dataset, the use of synthetic data also creates an opportunity to improve fairness. Since there often exist historical biases in the datasets, using the original real data for training can lead to an unfair model. Using synthetic data, we can attempt to remove such biases from the dataset before releasing the data. In this work, we formalize the definition of fairness in synthetic data generation and provide a general framework to achieve fairness. Then we consider two notions of counterfactual fairness and information filtering fairness and show how our framework can be used for these definitions.