|
Test-of-Time Award
|
This paper considers additive factorial hidden Markov models, an extension to HMMs where the state factors into multiple independent chains, and the output is an additive function of all the hidden states. Although such models are very powerful, accurate inference is unfortunately difficult: exact inference is not computationally tractable, and existing approximate inference techniques are highly susceptible to local optima. In this paper we propose an alternative inference method for such models, which exploits their additive structure by 1) looking at the observed difference signal of the observation, 2) incorporating a “robust” mixture component that can account for unmodeled observations, and 3) constraining the posterior to allow at most one hidden state to change at a time. Combining these elements we develop a convex formulation of approximate inference that is computationally efficient, has no issues of local optima, and which performs much better than existing approaches in practice. The method is motivated by the problem of energy disaggregation, the task of taking a whole home electricity signal and decomposing it into its component appliances; applied to this task, our algorithm achieves state-of-the-art performance, and is able to separate many appliances almost perfectly using just the total aggregate signal. |
|
Best Paper Award
|
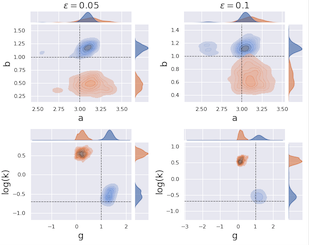
Simulator-based models are models for which the likelihood is intractable but simulation of synthetic data is possible. They are often used to describe complex real-world phenomena, and as such can often be misspecified in practice. Unfortunately, existing Bayesian approaches for simulators are known to perform poorly in those cases. In this paper, we propose a novel algorithm based on the posterior bootstrap and maximum mean discrepancy estimators. This leads to a highly-parallelisable Bayesian inference algorithm with strong robustness properties. This is demonstrated through an in-depth theoretical study which includes generalisation bounds and proofs of frequentist consistency and robustness of our posterior. The approach is then assessed on a range of examples including a g-and-k distribution and a toggle-switch model. |
|
Best Paper Award Nomination
|
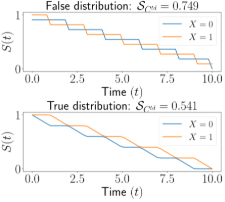
We consider frequently used scoring rules for right-censored survival regression models such as time-dependent concordance, survival-CRPS, integrated Brier score and integrated binomial log-likelihood, and prove that neither of them is a proper scoring rule. This means that the true survival distribution may be scored worse than incorrect distributions, leading to inaccurate estimation. We prove, in contrast to these scores, that the right-censored log-likelihood is a proper scoring rule, i.e. the highest expected score is achieved by the true distribution. Despite this, modern feed-forward neural-network-based survival regression models are unable to train and validate directly on right-censored log-likelihood, due to its intractability, and resort to the aforementioned alternatives, i.e. non-proper scoring rules. We therefore propose a simple novel survival regression method capable of directly optimizing log-likelihood using a monotonic restriction on the time-dependent weights, coined SurvivalMonotonic-net (SuMo-net). SuMo-net achieves state-of-the-art log-likelihood scores across several datasets with 20--100x computational speedup on inference over existing state-of-the-art neural methods and is readily applicable to datasets with several million observations. |
|
Best Paper Award Nomination
|

Common policy gradient methods rely on the maximization of a sequence of surrogate functions. In recent years, many such surrogate functions have been proposed, most without strong theoretical guarantees, leading to algorithms such as TRPO, PPO, or MPO. Rather than design yet another surrogate function, we instead propose a general framework (FMA-PG) based on functional mirror ascent that gives rise to an entire family of surrogate functions. We construct surrogate functions that enable policy improvement guarantees, a property not shared by most existing surrogate functions. Crucially, these guarantees hold regardless of the choice of policy parameterization. Moreover, a particular instantiation of FMA-PG recovers important implementation heuristics (e.g., using forward vs reverse KL divergence) resulting in a variant of TRPO with additional desirable properties. Via experiments on simple reinforcement learning problems, we evaluate the algorithms instantiated by FMA-PG. The proposed framework also suggests an improved variant of PPO, whose robustness and efficiency we empirically demonstrate on the MuJoCo suite. |
|
Best Paper Award Nomination
|
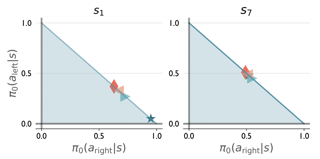
Much of the recent success of deep reinforcement learning has been driven by regularized policy optimization (RPO) algorithms with strong performance across multiple domains. In this family of methods, agents are trained to maximize cumulative reward while penalizing deviation in behavior from some reference, or default policy. In addition to empirical success, there is a strong theoretical foundation for understanding RPO methods applied to single tasks, with connections to natural gradient, trust region, and variational approaches. However, there is limited formal understanding of desirable properties for default policies in the multitask setting, an increasingly important domain as the field shifts towards training more generally capable agents. Here, we take a first step towards filling this gap by formally linking the quality of the default policy to its effect on optimization. Using these results, we then derive a principled RPO algorithm for multitask learning with strong performance guarantees. |
|
Best Paper Award Nomination
|
We consider frequently used scoring rules for right-censored survival regression models such as time-dependent concordance, survival-CRPS, integrated Brier score and integrated binomial log-likelihood, and prove that neither of them is a proper scoring rule. This means that the true survival distribution may be scored worse than incorrect distributions, leading to inaccurate estimation. We prove, in contrast to these scores, that the right-censored log-likelihood is a proper scoring rule, i.e. the highest expected score is achieved by the true distribution. Despite this, modern feed-forward neural-network-based survival regression models are unable to train and validate directly on right-censored log-likelihood, due to its intractability, and resort to the aforementioned alternatives, i.e. non-proper scoring rules. We therefore propose a simple novel survival regression method capable of directly optimizing log-likelihood using a monotonic restriction on the time-dependent weights, coined SurvivalMonotonic-net (SuMo-net). SuMo-net achieves state-of-the-art log-likelihood scores across several datasets with 20--100x computational speedup on inference over existing state-of-the-art neural methods and is readily applicable to datasets with several million observations. |
|
Best Paper Award Nomination
|
Common policy gradient methods rely on the maximization of a sequence of surrogate functions. In recent years, many such surrogate functions have been proposed, most without strong theoretical guarantees, leading to algorithms such as TRPO, PPO, or MPO. Rather than design yet another surrogate function, we instead propose a general framework (FMA-PG) based on functional mirror ascent that gives rise to an entire family of surrogate functions. We construct surrogate functions that enable policy improvement guarantees, a property not shared by most existing surrogate functions. Crucially, these guarantees hold regardless of the choice of policy parameterization. Moreover, a particular instantiation of FMA-PG recovers important implementation heuristics (e.g., using forward vs reverse KL divergence) resulting in a variant of TRPO with additional desirable properties. Via experiments on simple reinforcement learning problems, we evaluate the algorithms instantiated by FMA-PG. The proposed framework also suggests an improved variant of PPO, whose robustness and efficiency we empirically demonstrate on the MuJoCo suite. |
|
Best Paper Award Nomination
|
Much of the recent success of deep reinforcement learning has been driven by regularized policy optimization (RPO) algorithms with strong performance across multiple domains. In this family of methods, agents are trained to maximize cumulative reward while penalizing deviation in behavior from some reference, or default policy. In addition to empirical success, there is a strong theoretical foundation for understanding RPO methods applied to single tasks, with connections to natural gradient, trust region, and variational approaches. However, there is limited formal understanding of desirable properties for default policies in the multitask setting, an increasingly important domain as the field shifts towards training more generally capable agents. Here, we take a first step towards filling this gap by formally linking the quality of the default policy to its effect on optimization. Using these results, we then derive a principled RPO algorithm for multitask learning with strong performance guarantees. |
|
Best Paper Award Nomination
|
Simulator-based models are models for which the likelihood is intractable but simulation of synthetic data is possible. They are often used to describe complex real-world phenomena, and as such can often be misspecified in practice. Unfortunately, existing Bayesian approaches for simulators are known to perform poorly in those cases. In this paper, we propose a novel algorithm based on the posterior bootstrap and maximum mean discrepancy estimators. This leads to a highly-parallelisable Bayesian inference algorithm with strong robustness properties. This is demonstrated through an in-depth theoretical study which includes generalisation bounds and proofs of frequentist consistency and robustness of our posterior. The approach is then assessed on a range of examples including a g-and-k distribution and a toggle-switch model. |